



Photo by Campaign Creators on Unsplash
Can we use database as queue in asynchronous process ?
When all you have is a hammer, every problem looks like a nail.


“When all you have is a hammer, every problem looks like a nail.”
Introduction
In the previous post, we saw about synchronous and asynchronous request-response cycle. and we know the benefits of using asynchronous mechanism for a bigger tasks. In this post we will try to design a producer-consumer model with what we have in our mind using a database (RDBMS).
TL,DR;
Don't use RDBMS for implementing asynchronous process. There are some dedicated softwares (Message Queues) written for them to solve the problem.
Database as a Queue
Developers try to use their RDBMS as a way to do background processing or service communication. While this can often appear to 'get the job done', there are a number of limitations and concerns with this approach.
There are two divisions to any asynchronous processing: the service(s) that create processing tasks and the service(s) that consume and process these tasks accordingly.
In the case of using a database as a method for this, typically there would be a database table which has records that represent notified tasks and then a flag ("Queued", "In Progress", "Finished", "Error") to represent the which state the tasks is in and whether the task is completed.
Scenario based example
Let's try to design a asynchronous mechanism with database on an application, where the user can convert their PDF to Word file (like zamzar.com).
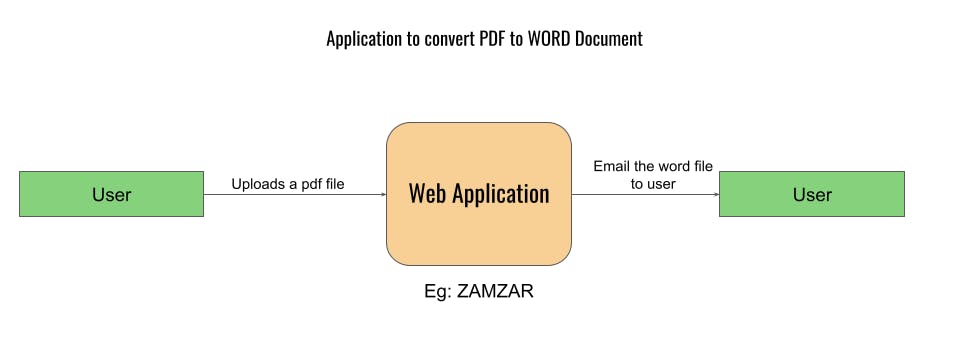
Process flow:
- Customer uploads a pdf file
- Your application converts the pdf file into a word file.
- Your application emails the word file back to the customer
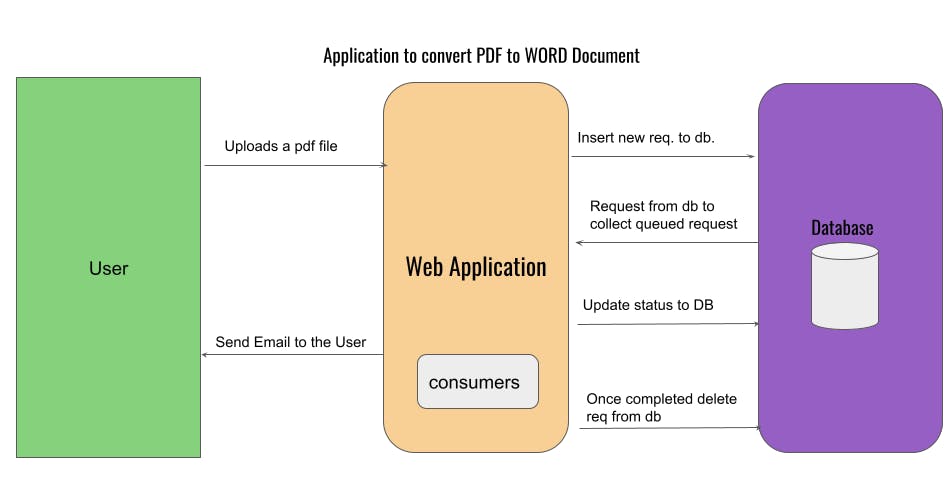
In this kind of situation, you might consider using a database for your Word Conversion job queue. Typically you would create a database table that has a queue with records representing Word conversion requests. You would then place a flag in the table representing which state the task is in and whether the task is completed or not.
INSERT INTO word_job_queue (name, status, email) VALUES ("White paper", "Queued", "myemail@example.com");
You need to write below code logic's to complete the process,
- Code to insert the new request to the database with status as QUEUED.
- Code to check the Queued request and process the request.
- Code to update the status of the request. (Inprogress, Completed, Error).
- Code to remove the request from the database.
Another thing that you should keep in mind when you build a solution where you let your database act as a queue, is that your application has to ask the server over and over again for the latest queued requests. Messages that have already been consumed need to be filtered out.
The database table is both read from and written to. Usually, it is a quick operation to add, update or query data from a table, but now you will have to deal with all of these happening in the same table. Queuing/dequeuing will impact each other under heavy loads, causing lock conditions, transaction deadlocks, IO timeouts, etc.
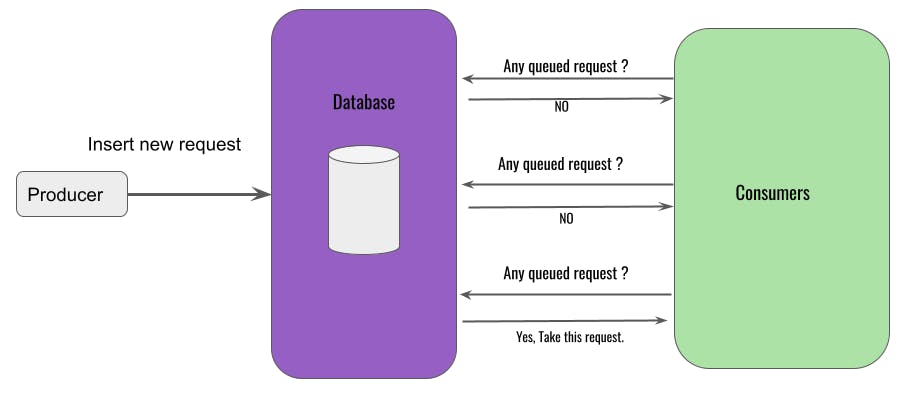
Polling Problems
With a traditional database this typically means a service that is constantly querying for new processing tasks or messages. The service may have a database poll interval of every second or every minute, but the service is constantly asking the database if there has been an update. Polling the database for processing has several downsides. You might have a short interval for polling and be hammering your database with constant queries. Alternatively, you could perhaps set a long interval in which case there will be many unnecessary processing delays.
Multiple Consumers
When there are multiple consumers to process the requests exists and if you are constantly inserting, updating and querying, race conditions and deadlocks become inevitable. These ‘locks’ occur because multiple consumers will all be “fighting” with each other over the same table and with the ‘producers’ constantly adding new items. You will see load increase for the database, performance decrease and pile-ups become increasingly common as the volume scales up.
Clean up of completed requests
In addition to that, clearing old jobs can be troublesome as well because at even a medium volume, there will be many tasks in the database table. At certain intervals, the old completed tasks need to be removed otherwise the table will grow quite large. Unfortunately, this has to be performed manually and deletes are even often not particularly efficient for tables especially when being removed so frequently in conjunction with updates and queries all happening at the same time.
Scaling Won't be easy
In the end, while a database that appeared to work in developer machine for a small test, won't do well in production. The limitation such as constant polling, cleanups of completed tasks, deadlocks and handling of failed process would make it difficult to scale the database for this type of process mechanisms.
Isolation Levels
Since its a database, there can be a scenario where two or more consumers might work on the same request. In order to avoid this, we may introduce some isolation levels. By introducing isolation levels, we would be blocking the consumers to take requests concurrently.
Using database as queue is an anti-pattern
- Sharing a database between applications (or services/consumers) is a bad thing.
- Process of clearing records once the workflow is complete. If you don’t clear the table down at intervals, it will keep growing until it starts to hit the performances of your queries and eventually become a serious operations problem.
- Locks can become a major problem.
- Isolation can stop the consumers, working parallely.
- Hammering the database for constant intervals for read, insert, update.
Final thoughts
Using a database as a queue can be simpler to setup and probably easier to test on a development machine. But running a database as a queue in production may not be a very good idea; especially in a high traffic scenario.
An asynchronous processing mechanism is useful whether you need to send an sms, validate emails, approve posts, process orders, or just pass information between services. This type of background processing is simply not a task that a traditional RDBMS is best-suited to solve. There is a different class of software that was built from scratch for asynchronous processing use cases. This type of software is called a message queue and you should strongly consider using this instead for a far more reliable, efficient and scalable way to perform asynchronous processing tasks.
In upcoming post's we will see about message queues such as RabbitMQ, ZeroMQ and more items.